
探索 Pytorch 调参的起点之谜

60
在当今的科技领域,Pytorch 作为一种强大的深度学习框架,被广泛应用于各种项目中,对于许多开发者和研究者来说,Pytorch 调参却是一个令人头疼的问题,究竟应该从何处开始进行 Pytorch 调参呢?
要解决这个问题,我们需要先了解 Pytorch 调参的一些基本概念,调参并非是随意的尝试,而是有一定的规律和方法可循,比如说,学习率的设置就是一个关键因素,学习率过大,可能会导致模型无法收敛;学习率过小,则会使训练过程变得异常缓慢。
数据的预处理也不能忽视,数据的质量和预处理方式会直接影响模型的训练效果,对数据进行清洗、归一化、增强等操作,可以让模型更好地学习到数据中的特征和规律。
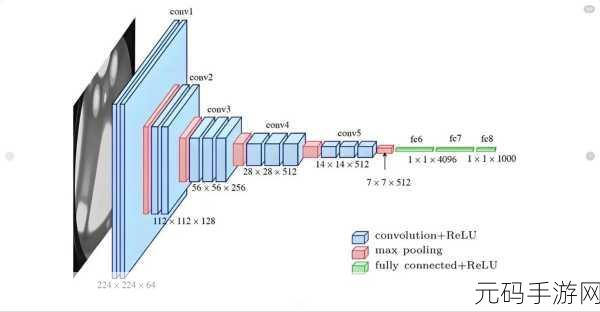
模型的架构选择同样至关重要,不同的模型架构适用于不同的任务和数据类型,选择合适的模型架构,可以大大提高调参的效率和模型的性能。
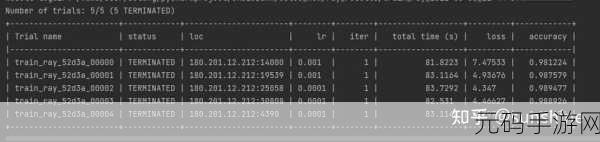
超参数的调整也需要技巧,除了学习率,还有诸如正则化参数、层数、节点数等超参数需要仔细斟酌,可以通过试验不同的组合,观察模型在验证集上的表现,来找到最优的超参数组合。
在实际调参过程中,要善于利用各种工具和技巧,使用自动调参工具可以节省大量的时间和精力,多参考前人的经验和研究成果,也能让调参之路更加顺畅。
Pytorch 调参是一个需要不断实践和探索的过程,只有掌握了正确的方法和技巧,才能让模型达到最佳的性能。
文章参考来源:深度学习相关研究文献及技术论坛。
最新文章

神仙道失却之阵等级上限突破,全新上限等级揭秘
2025-03-14
神武2五庄技能全解析,揭秘最强战斗秘籍
2025-03-14
泰拉瑞亚鱼鲨坐骑全攻略,获取、管理与价值最大化
2025-03-14
冰封奇境,猎怪新章——怪物猎人冰风探秘手游重大版本更新深度解析
2025-03-14
阴阳师记忆星盘揭秘,式神背景与动人故事深度探索之旅
2025-03-14
热门文章


草莓视频在线免费观看软件下载:1. 草莓视频在线免费观看:畅享海量影视资源的最佳选择
2024-12-25羞羞网站在线观看入口免费:1. 探索羞羞网站的无限精彩与乐趣
2024-12-2851黑料入口吃瓜:1. 51黑料入口揭秘:娱乐圈不为人知的秘密
2024-12-23
182TtV福利:1. 182TtV福利:全面提升您的生活品质与享受
2024-12-26
污污软件免费下载:1. "污污软件免费下载:畅享无限资源与乐趣
2024-12-31