
深入探索,Kafka 序列化与反序列化对大数据处理的关键影响

40
在当今数字化时代,大数据处理已成为众多企业和组织面临的重要任务,而 Kafka 作为一种强大的分布式消息队列系统,其序列化和反序列化机制在其中发挥着至关重要的作用。
Kafka 中的序列化和反序列化是实现高效数据传输和存储的核心环节,序列化将复杂的数据结构转换为字节序列,以便在网络中传输或存储到磁盘,反序列化则是将接收到的字节序列重新转换为原始的数据结构,供后续的处理和分析使用。
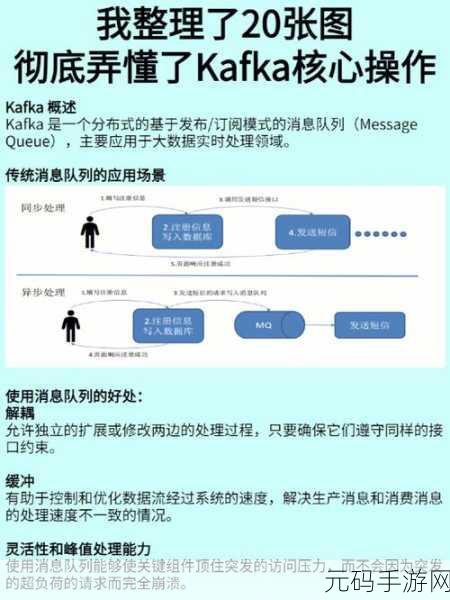
Kafka 序列化和反序列化的优势在于其高效性和灵活性,高效的序列化和反序列化能够大大提高数据处理的速度,减少系统的资源消耗,Kafka 支持多种序列化和反序列化的方式,如 Avro、JSON、Protobuf 等,用户可以根据具体的业务需求和数据特点选择最合适的方式。
在实际应用中,合理配置 Kafka 的序列化和反序列化参数至关重要,调整序列化的压缩算法可以在减少数据传输量的同时,不显著增加处理时间,对于数据的准确性和完整性要求较高的场景,选择具有强校验机制的序列化方式能够有效避免数据错误。
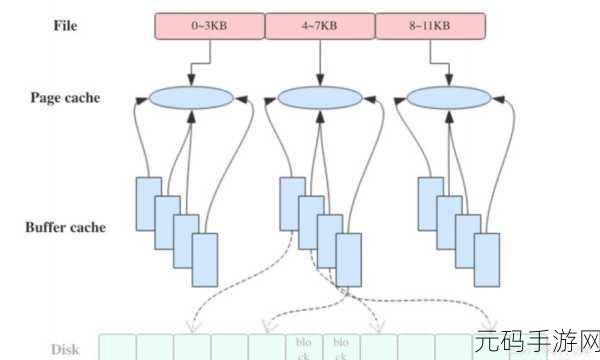
为了充分发挥 Kafka 序列化和反序列化在大数据处理中的作用,还需要考虑数据的分区和副本策略,合理的分区能够确保数据在不同节点上的均衡分布,提高处理效率;而适当的副本数量则可以保证数据的可靠性和可用性。
深入理解和掌握 Kafka 序列化和反序列化机制对于优化大数据处理流程、提高系统性能具有重要意义,只有在实践中不断探索和优化,才能让 Kafka 在大数据处理领域发挥出更大的价值。
文章参考来源:相关技术文档和大数据处理领域的研究报告。
最新文章

神仙道失却之阵等级上限突破,全新上限等级揭秘
2025-03-14
神武2五庄技能全解析,揭秘最强战斗秘籍
2025-03-14
泰拉瑞亚鱼鲨坐骑全攻略,获取、管理与价值最大化
2025-03-14
冰封奇境,猎怪新章——怪物猎人冰风探秘手游重大版本更新深度解析
2025-03-14
阴阳师记忆星盘揭秘,式神背景与动人故事深度探索之旅
2025-03-14
热门文章


草莓视频在线免费观看软件下载:1. 草莓视频在线免费观看:畅享海量影视资源的最佳选择
2024-12-25羞羞网站在线观看入口免费:1. 探索羞羞网站的无限精彩与乐趣
2024-12-2851黑料入口吃瓜:1. 51黑料入口揭秘:娱乐圈不为人知的秘密
2024-12-23
182TtV福利:1. 182TtV福利:全面提升您的生活品质与享受
2024-12-26
污污软件免费下载:1. "污污软件免费下载:畅享无限资源与乐趣
2024-12-31